
Surrendering to FOMO on important AI “breakthroughs”, I subscribed to the arXiv mailing list. Like all subscribers, I can’t read all the submissions in the daily email. To be completely honest, I simply archive the email from my inbox every day without even opening it. There is a slight chance that I try to browse through titles and abstracts one by one. But I wouldn’t be able to read more than 10 abstracts. There are simply too many to read through.
Then I came up with the idea to create a paper recommendation service for myself. At this scale, I think it could be a fun weekend project to code up anyway. Surprisingly, it actually took much less time than I anticipated, with the help of ChatGPT.
How it looks
Now when I got few minutes, I would go to https://pppoe.github.io/ArxRec/ to checkout the 10 submissions it recommended to me from the piles of submissions to arXiv in the past 48 hours.

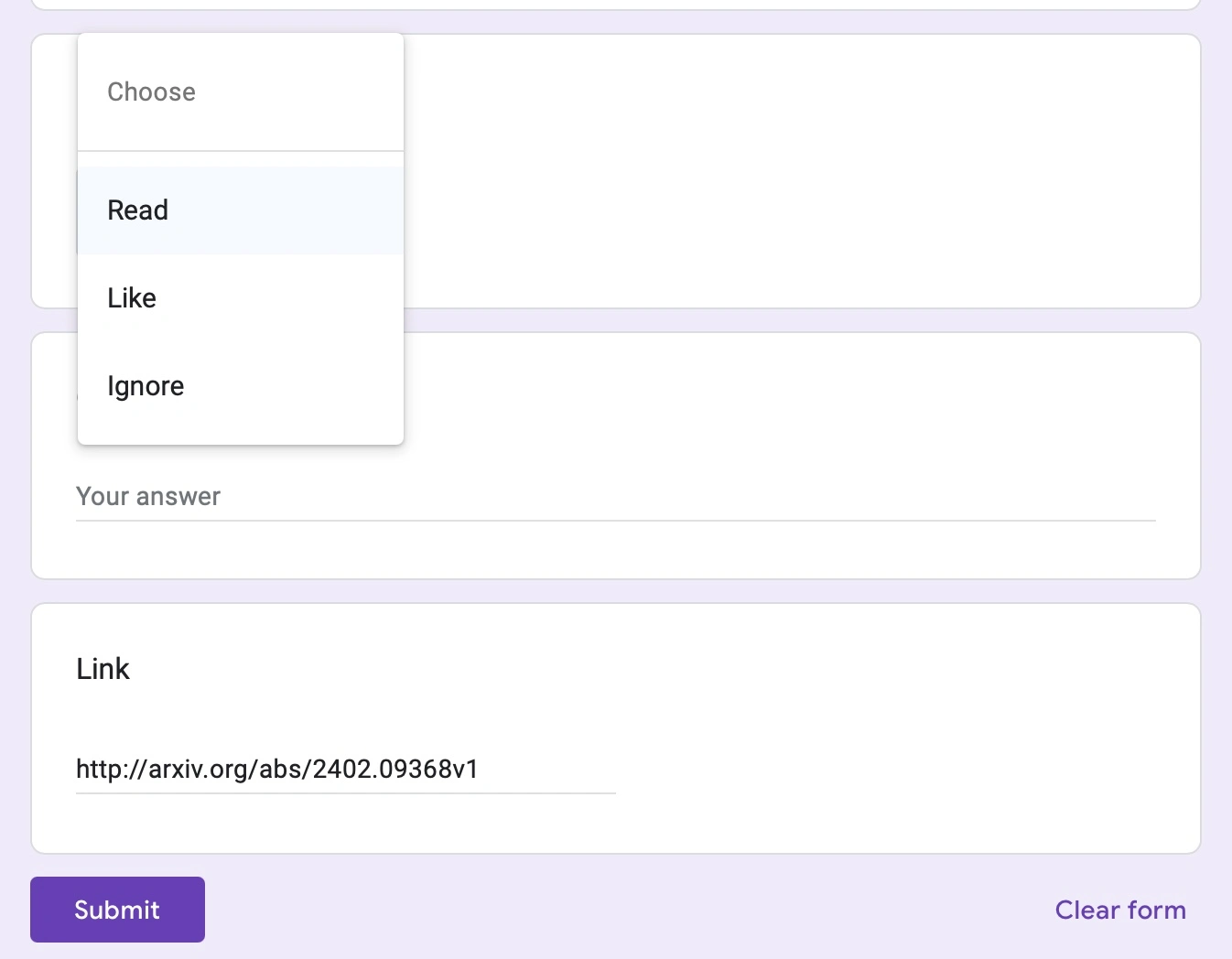
If there is something I would like to read, I follow the link to read paper on arXiv. After that, if I’d like ArxRec to give me “more like this”, I follow the “Action” button to provide feedback on this paper.

This is a Google form. Currently I preset 3 ratings and it is so far good enough. “Read” is the highest and “Ignore” can be used to mark irrelevant recommendations.
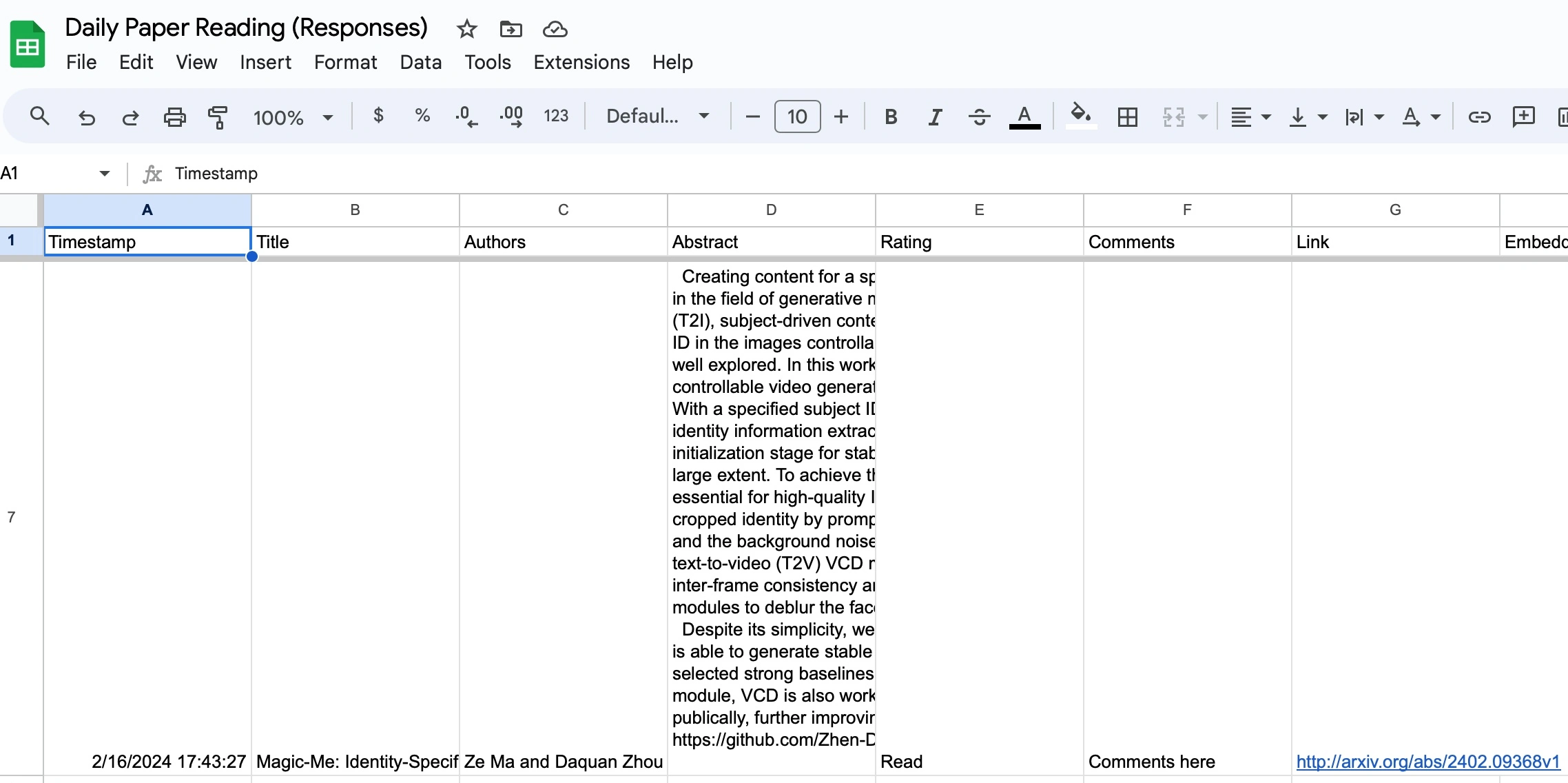
All feedbacks are recorded in a Google sheet linked to the form where I can always go to find the marked ones there.
How it is implemented
The website is hosted on Github page from a public repo: https://github.com/pppoe/ArxRec and the source code is there.
Functionality-wise it is quite straightforward. Although the recommendation is personalized, because I am the only user here, there is no online computation in anyway. Everything is computed offline periodically on my PC and submit to Github to serve the generated static HTML file.
The crontab job did the following things:
- Fetch submissions from arXiv
- Fetch my past responses from Google forms
- Extract Text Embeddings from Open AI’s model
- Rank submissions and generate the daily webpage
- Submit to Github to serve
ChatGPT saved me lots of time here. It generated the boilerplate code to query Arxiv and Google form. Though the code does not work out-of-the-box, it’s much easier to understand the APIs by looking the code than reading the documentation.
The recommendation is based on a pool of papers consists of my recent publications crawled from Google Scholar and the ones with my feedbacks submitted from the Google form. Relevancy of an arxiv submission is a simple weighted sum of its similarities to the papers in the pool. The similarity between two papers is the cosine similarity of their text embeddings.
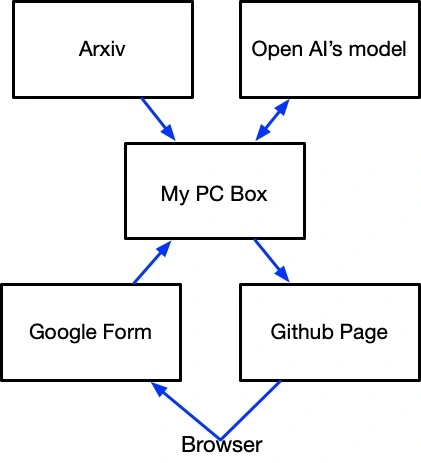
One must-have functionality of this service to allow me to easily give feedback and use of Google form simplifies the implementation. I put a flow chart below. Because there is no direct interaction between end user and the PC box, I can skip implementing and maintaining a backend.
I had a concern on the cost to use OpenAI’s API in the beginning. However, after running this for a few days, the cost is quite limited. On average, the number of tokens to get text embedding for one paper is around 300 including its title, authors, and abstract. The current pricing is at $0.00002/k tokens so a pre-paid $10 can possibly keep it running for a few years.
I canceled my meaningless subscription to the mailing list and have been using this happily for a couple of weeks so far. The good thing is that I can make whatever tweaks I need. If I move the daily job to Github CI, I can even take my PC box out from the flow chart above to have everything running on free public tools.

I am not sure if all the worries about developers being replaced by AI are legitimate or over-reaction. But nowadays, building tool is indeed easier with these LLMs.
Webmentions
minoxidil onset vs duration
minoxidil onset vs duration
minoxidil men’s beard growth
minoxidil men’s beard growth
minoxidil foam vs liquid formulation comparison
minoxidil foam vs liquid formulation comparison
minoxidil common questions
minoxidil common questions
minoxidil evidence‑based guide
minoxidil evidence‑based guide
ivermectin rosacea peer‑reviewed data
ivermectin rosacea peer‑reviewed data
toradol migraine duration
toradol migraine duration
terbinafine for chronic nail fungus
terbinafine for chronic nail fungus
ketorolac tromethamine absorption
ketorolac tromethamine absorption
acular ketorolac
acular ketorolac
orlistat for sale
orlistat for sale
bupropion hcl vs xl
bupropion hcl vs xl
minoxidil watsons review
minoxidil watsons review
flagyl antibiotic no alcohol
flagyl antibiotic no alcohol
vardenafil tadalafil combo
vardenafil tadalafil combo
finns semaglutid naturligt
finns semaglutid naturligt